Research Article - Onkologia i Radioterapia ( 2025) Volume 19, Issue 6
MCRIP-UNet: A modified U-Net architecture for semantic segmentation of images for breast cancer detection
Pothina Praveena* and N. Suresh KumarPothina Praveena, Department of CSE, GIT, GITAM (Deemed to be University), Andhra Pradesh, India, Email: ppothina@gitam.edu
Received: 02-Jan-2025, Manuscript No. OAR-25-161074; , Pre QC No. OAR-25-161074; Editor assigned: 07-Jan-2025, Pre QC No. OAR-25-161074; Reviewed: 21-Jan-2025, QC No. OAR-25-161074; Revised: 05-Aug-2025, Manuscript No. OAR-25-161074; Published: 02-Sep-2025
Abstract
We detail a deep learning architecture that performs an effective nuclei segmentation and recognition without much intervention with the system from images stained by MCRIP-UNet for breast cancer. Based on deep learning, MCRIP UNet is a multi-dimensional cross-reconstruction inverted pyramid network introduced for enhancing precision as well as acceleration in the field of medical image segmentation. Three different encoder architectures are applied to extract feature information from each modality by using multimodal magnetic resonance images as input. At the same resolution level, the retrieved feature data is first fused. A dual band cross reconstruction attention module is used for multimodal feature fusion and refinement. In order to achieve the goal of breast tissue segmentation, a pyramidal-shaped decoder is used at each stage of the decoder to integrate the features of different resolutions. It is proved by comparing the segmentation results of data that the modified algorithm greatly improves the effect of segmentation besides having simple interaction and fast speed compared with the confidence connection method. The experimental results show that this model is more accurate compared to the other models and the state-of-the-art conventional U-Net network.
Keywords
Breast cancer; Semantic segmentation; U-Net; Breast image; Pyramidal network
Introduction
Breast cancer is a widespread and deadly illness around the world, characterized by high mortality rates resulting from abnormal cell proliferation [1. Detecting the disease early is vital for enhancing patient survival rates, highlighting the necessity for effective diagnostic techniques. The healthcare system plays a crucial role by guaranteeing precise diagnoses, treatments and improved care while lessening dependence on specialized personnel [2]. The incorporation of cutting-edge technologies in healthcare is essential for advancements in medical research.
Recent progress in Machine Learning (ML) and Deep Learning (DL) has greatly enhanced the detection of breast cancer. DL employs multi-layered Artificial Neural Networks (ANNs) that learn hierarchical representations of data [3]. A significant concept in DL, Transfer Learning (TL), uses pre-trained models to extract features from extensive datasets, accelerating the training process and boosting performance. This methodology is especially advantageous in diagnosing breast cancer, as pre-trained models can capture intricate features from large datasets, thereby improving model efficacy despite the scarcity of data [4,5].
ML algorithms facilitate the prediction of patterns within data by examining extensive labeled datasets, providing a robust foundation for better patient care and diagnostic precision [6-8]. In the realm of breast cancer screening, feature extraction from medical images is a critical component. This procedure focuses on identifying and gathering relevant patterns, including statistical metrics, texture and shape characteristics, to differentiate between healthy and cancerous cells. Precise feature extraction is crucial for detecting breast cancer and planning treatment [9-12].
T his paper presents the UNet model, a single-level method for the detection, segmentation and classification of abnormal masses in mammograms. Each pixel is categorized as benign, malignant or normal, without the need for prior processing or pre-trained model weights. The suggested approach merges Convolutional Neural Networks (CNN) and Transformer structures with morphological constraints for 3D medical image segmentation [13]. The UMP Unet model, which builds on the TransUNet architecture, improves multi-objective joint detection by integrating morphological structure learning [14-16].
To assess this methodology, two publicly available datasets were utilized. The study unfolds through various stages: Phases 2 and 3 detail earlier and current segmentation methods, while phases 4 and 5 address dataset training, model evaluation and segmentation results. Section 6 discusses the advantages, limitations and future research directions for the proposed approach.
Increased mammographic breast density presents a notable risk factor for breast cancer, making precise, automated assessments of breast density essential for the clinical use of FFDM. A newly introduced automated measure of Percent Breast Density (PBDa) was evaluated against the operator-assisted measure (PD) for determining breast density [17,18]. The research employed conditional logistic regression and BMI-adjusted analyses to calculate the Odds Ratios (ORs) for breast cancer, with SDN analysis revealing that PDa must account for a nonlinear relationship between the mammographic signal and its variance.
A comparison was made between the effectiveness of SVM and ANN in classifying breast cancer tumors, where SVM reached a classification accuracy of 91.6% using radial functions, while ANN obtained 76.6%. As a result, SVM was utilized to assess outcomes associated with breast cancer risk factors. Factors such as bereavement, social connections, regret and emotional attachment were found to significantly impact the mental well-being of breast cancer patients [19,20].
A novel hybrid approach for breast cancer detection was proposed, integrating Deep Learning (DL) with ensemble-based machine learning algorithms, which utilized a pre-trained ResNet50V2 model. This model achieved an accuracy of 95%, with a precision of 94.86%, recall of 94.32% and an F1 score of 94.57%, surpassing previous models. The study also compared the effectiveness of various models, including ANN, restricted Boltzmann machines, deep autoencoders and CNNs, in post-operative survival analysis, with deep autoencoders ranking second in accuracy after the restricted Boltzmann machine.
A technique based on U-Net for extracting Regions of Interest (RoI) from mammograms displayed remarkable results, achieving an accuracy of 86.71% and a recall of 91.34% when assessed using the CBIS-DDSM dataset. An advanced high-resolution multi-view deep CNN combined with fuzzy logic was introduced for breast cancer detection, demonstrating improved reliability and speed over earlier segmentation approaches [21].
T he superiority of ensemble methods over single networks was evidenced, with an accuracy of 91% in classification and a dice coefficient of 82% in segmentation evaluations. A range of machine learning techniques, including naïve Bayes, KNN, SVM and decision trees, has been investigated for breast cancer classification, with deep learning emerging as increasingly significant in recent research. A study that utilized ResNet18, InceptionV3 and ShuffleNet for classifying histopathology images reached the highest accuracy of 98.73% using ResNet18. Transfer learning incorporating CNNs like VGG19, ResNet34 and ResNet50 demonstrated notable improvements in accuracy, with ResNet50 attaining 92.07% accuracy while requiring fewer FLOPs.
Deep learning methodologies have shown potential in decreasing reading times and enhancing breast cancer detection accuracy. CNNs have been employed to differentiate breast tissue as benign or malignant, with a model trained on the mini-MIAS dataset achieving 95.71% accuracy, exceeding the performance of current frameworks. AI-driven computer vision strategies are aiding in overcoming the constraints of traditional diagnostic techniques and integrating patient data along with radiographic information can improve the precision of models [22]. Pseudo-class component prototype networks have been suggested to boost classification accuracy and interpretability by 8% and 18%, respectively. Additionally, AI is being examined for its role in patient education and supporting healthcare professionals in making breast cancer
Materials and Methods
T he neural network known as 3D U-Net features symmetrical encoders and decoders [23]. To enhance resolution features, 3D U-Net’s encoder and decoder integrate features of identical resolution through skip connections [24]. Additionally, the architecture of 3D U-Net employs 3D convolution, maximum pooling and deconvolution to process 3D medical image data [25]. This approach improves segmentation quality by capturing the 3D spatial information contained within an image. Attention mechanisms have been applied in various ways for medical image segmentation. For the segmentation of small sublingual veins, Yang et al. [26] introduced an interactive attention network capable of intuitively recognizing the topology of the target vein for segmentation. In the decision level fusion network [27], each modality image serves as one input to a unified segmentation network and the overall segmentation result emerges from the integration of the outputs from each individual network. Input level fusion networks [28] typically stack multimodal images along the channel dimension to develop fused features for training segmentation networks. This paper takes advantage of the input level fusion network to fully leverage the feature representation of multimodal images. Given that the network adeptly preserves the original image information while extracting its intrinsic features, the development of this work is grounded in that insight. This research incorporates a dual channel cross-attention method at the input stage of the fusion network, which facilitates both the integration of multimodal characteristics and a focus on the details of the breast, enabling the network to prioritize important information.
Improved multi graph segmentation algorithm
For Linux systems, python-based packages can be directly utilized for registration tasks. The constraints for registration are relaxed by ANTs and 21 different registration approaches. Four key values in the registration process include the results from registering the f loating image to the fixed image, the outcomes from the fixed image registration to the floating image, the transformation matrix for floating to fixed image registration and the transformation matrix for fixed to floating image registration. In the experiment, the data is used to derive the registration outcome from floating image registration to the fixed image. When using the image analysis tools available in ANTs, employ the default parameter settings and choose the ‘SyN’ registration algorithm. Real time performance is essential for medical image segmentation. T hus, deformable registration networks can significantly shorten registration time while maintaining registration accuracy when deep learning methods replace traditional "precision" registration techniques. Figure 1 depicts the image registration framework enhanced by deep learning. The fixed image and floating image are input into a deep learning registration network to generate the registration deformation field. The deformation field is then applied to the target image through the spatial transformation network. To form the complete registration model, network parameters are continuously updated using the registration image and Loss function. The foundational registration network is augmented with an ECA attention mechanism network to boost the feature strength of the target image block, concentrate on ROI features and eliminate unnecessary features. Consequently, the network extracts a more significant feature map; to capture multi-scale information, cavity convolution is introduced, expanding the Receptive field; a 3 × 3 × 3 model is developed for the Loss function. Adjustments are made to the network settings, image navigation and registration accuracy is enhanced. While incorporating attention modules improves the performance of the network model, it inevitably increases the model's complexity. Wang, et al. [29] introduced the ECA attention mechanism, which finds a balance between complexity and performance. The main modifications that ECA Net made to SE Net involve a local channel mutual strategy that minimizes dimensionality and can be efficiently executed using one dimensional convolution. In contrast to SE attention, which first compresses channels to lower dimensionality and compress input feature maps, this compression adversely impacts the dependence relationships among the channels being learned. Consequently, the ECA attention mechanism utilizes one-dimensional convolution instead of dimensionality reduction to effectively capture the dependence connections between channels and their local interactions. Figure 1 illustrates its structure.

Fig. 1. ECA attention model.
It is evident that, when compared to other attention mechanisms, ECA provides both performance and efficiency in the model while minimally affecting the network's processing speed. Thus, the ECA attention mechanism is employed to enhance the network more effectively and efficiently, achieving performance optimization by adaptively acquiring global correlations from both the spatial and channel perspectives. To address the decline in image quality that occurs when U-Net networks down sample, this paper improves the approach through the use of dilated convolution [30] to mitigate information loss. Initially, this helped resolve some image segmentation issues with the introduction of cavity convolution.
However, segmentation accuracy suffers due to pixel loss during the initial image reduction step. Therefore, hollow convolution was implemented to tackle this problem. The receptive field is typically defined as the area where a single pixel in the feature map corresponds with its input map [31]. A larger receptive field enables the extraction of more contextual and feature information. As illustrated in Figure 2, hollow convolution increases a hyperparametric hole rate, also known as the dilation rate, which corresponds to the amount of inter cores in relation to standard convolution.

Fig. 2. Convolution of cavities and receptive fields a) 3 × 3 kernel with 1 void rate, b) 3 × 3 kernel with 2 void rate and became 7 × 7 kernel, c) 3 × 3 kernel with 4 void rate and became 15 × 15 kernel.
Hollow convolution offers the benefit of enabling the network model to acquire additional feature information for each convolution while retaining all existing data. As a result, implementing hollow convolution can enhance both training accuracy and speed by extracting features from the intricate areas of the image. By utilizing two channels, the experimental approach boosts the performance variability of the decoder by capturing twice the number of image features compared to the original U-Net. The core structure of the network is depicted in Figure 3 as a convolutional network, which is parameterized similarly to a U-Net CNN. This transcoder decoder architecture, featuring skip connections, comprises 4 down sampling and 4 up sampling layers and is designed to compute deformation fields φ using given fixed and floating images. Hollow convolution is incorporated at the network's base to increase the receptive field and enhance feature correlation. The addition of cavity convolution targets the reduction of feature information loss during the down sampling stage. With an expansion rate of 2, it introduces two zeros into the convolution kernel and broadens the receptive field to capture multiscale information, facilitating the extraction of hippocampal features and further boosting training speed and accuracy.

Fig. 3. Network for spatial transformation.
T he initial coder consists of four down sampling modules. To improve the feature extraction capabilities of the coder, an ECA module has been incorporated into each of the four down sampling modules in this study following each down sampling step. After the features were initially extracted and the ECA module was integrated, an ADD addition step was introduced before proceeding with ECA processing. This was then connected to the up sampled feature layer to capture more detailed features and improve the model's performance. EDDnet is capable of modeling the function, accepting both fixed and floating images as inputs and predicting the displacement vector field in an end to-end manner. During the training phase, the moving image M and the displacement vector field are utilized, while the training process seeks to optimize the parameter count by minimizing the phase loss between the curve image and the fixed image F, along with the regularization loss of the displacement vector field. The curve image is generated through a curving process. As illustrated in Figure 4, the components of the operational mechanism of a spatial transformer include the localization network, grid generator and sampler.

Fig. 4. Two types of residual modules: Standard and enhanced.
Principle of rib image segmentation
T he U-Net architecture is a fully convolutional network specifically crafted for segmentation tasks, employing both down sampling and up sampling stages. The down sampling section utilizes a series of 3 × 3 convolutions and 2 × 2 pooling to gradually extract intricate spatial features. In the up sampling phase, deep feature maps are smoothed and combined with shallow features, which are vital for effective segmentation, particularly in medical contexts where shapes are consistent and semantic complexity is low. Skip connections improve feature extraction at shallower levels, resulting in more precise segmentation outcomes [32].
To tackle the problem of under segmentation, particularly in identifying small fractures within intricate images, the Squeeze and Excitation (SE) module is implemented [32]. This module enhances feature maps by prioritizing significant features while diminishing irrelevant ones. It operates by utilizing global average pooling to create channel-wise weights, which are subsequently employed to scale the features through an excitation function. This approach boosts model accuracy without a considerable increase in computational demands.
For volumetric segmentation, the network utilizes pyramid pooling to broaden the receptive field and capture information at multiple scales [32]. Following four subsampling steps, the pyramid pooling module merges features from various scales, enriching the model with a wider spatial context. This technique, analogous to U-Net's skip connections, enhances segmentation by fusing local and global feature details.
In the 3D RSPU Net, the integration of residual structures improves segmentation performance, while maintaining balance in both encoding and decoding processes, starting with an initial feature extraction stage that uses 3 × 3 × 32 convolutions (Figures 5 and 6).

Fig. 5. Module of squeeze and excitement.

Fig. 6. FTFramework for 3D RSPU-Net.
T he architecture features four groups of modules in the encoding portion, each containing a SE structure along with a down sampling module. These modules include two convolution operations, where the SE component enhances channel count, thereby significantly boosting segmentation performance [32]. In the decoding portion, there are also four module groups designated for up sampling, each incorporating an SE structure. The input for this up sampling process originates from both the preceding decoder layer's output and the corresponding encoder output. At each stage, there is a twofold increase in down sampling channels and a twofold decrease in resolution. Following three down sampling stages, a pyramid pooling module is introduced, comprising four parallel average pooling layers with receptive fields of 1, 2, 3 and 6 to capture more comprehensive contextual features [32]. Skip connections that link shallow features of the encoder with deep features of the decoder assist in the integration of these features (Figure 7) [32].

Fig. 7. Diagram of the proposed network structure.
T he TransUNet network design combines Transformer and CNN architectures for enhanced segmentation capabilities. This method for three-dimensional medical image segmentation employs joint network learning alongside morphological structure constraints. A morphological structure constraint module utilizes prior morphological information to extract the shape characteristics of the segmented objects. The U-shaped TransUNet design effectively leverages both low-level surface and high-level abstract features for better segmentation outcomes [32].
T he encoder applies CNN for feature extraction, followed by maximum and average pooling after every ResBlock module. These extracted features are then directed into the morphological structure module. A transformer subsequently processes these features to derive both global and local context. Skip connections and cascade up sampling integrate features from corresponding levels [32]. This approach's primary advantages include enhanced segmentation accuracy through the merger of local and global features, leading to improved precision, resilience and generalizability of the model.
Transformers implement a self-attention mechanism that prioritizes weight on target regions for segmentation, concentrating more on the target while utilizing CNN for feature extraction [32]. Merging CNN with transformer results in superior segmentation performance by integrating combined information from both. A joint segmentation methodology is utilized to simultaneously segment multiple targets, allowing for information supplementation across tasks. This approach also includes a module dedicated to extracting shape data from 3D medical images, facilitating edge recovery for organs, tissues and structures through edge extraction methods. Convolution operations enhance the precision of the f inal shape information, thereby improving the robustness and generalizability of the segmentation model [32].
Results
Dataset description
T he Breast Cancer Semantic Segmentation (BCSS) dataset contains over 20,000 annotations that delineate regions of breast cancer tissue, all obtained from TCGA [33]. The dataset has been resized to dimensions of 224 × 224 and 512 × 512 pixels for the respective versions. While the 512 × 512-pixel version offers greater detail and accuracy, the 224 × 224-pixel version is designed to support the development of machine learning models for tissue segmentation with enhanced computational efficiency. Slides are annotated collaboratively by pathologists, residents and medical students, utilizing the digital slide archive (Figure 8). This dataset serves as a distinctive learning resource to improve precision and experiment with data applications. It proves to be an excellent asset for research focused on training models and analyzing slides. In this study, we explore novel approaches to crowdsourcing for large-scale data generation and highlight the significance of such data for the training of semantic segmentation neural networks. Creative applications of this dataset include enhancing predictions for rare classes, integrating it with other datasets or discovering new pathomic and genetic biomarkers. Figure 9 displays some representative samples from the BCSS dataset.

Fig. 8: Some samples of BCCS dataset.

Fig. 9: Dice score and Jaccard coefficients obtained with proposed model.
Tools and hardware
T he experiments detailed in this paper were conducted using the open-source tensor flow framework. The system is equipped with two NVIDIA GeForce GT1080ti graphics cards, each featuring 8 GB of memory, running on a 64-bit Windows architecture. The initial learning rate for the network model is established at 0.001, with the total number of iterations for weight updates set at 50 and the learning rate halved every 10 iterations of weight changes. Tests were conducted to enhance the evaluation of the proposed network model by utilizing one of the well-known medical breast image datasets: BCCS. the varying levels of white matter damage among diabetes patients within the BCCS dataset are illustrated. In the experiments discussed in this paper, the data is allocated as 10% for validation, 10% for testing and 80% for training purposes. Each image underwent deviation correction and medical professionals manually segmented the targeted images.
T he segmentation efficiency of the network for breast tissues is assessed using the three most widely used evaluation indicators in order to assess the efficacy and dependability of the algorithm presented in this research. The Sørensen-Dice Coefficient (DC) is one of the three indicators. Hausdorff Distance (HD) and Absolute Volume Difference (AVD). Their formulas are shown in formula (1).
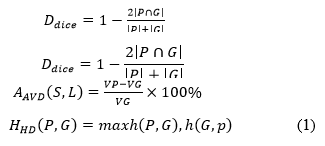
T he segmented image of the prediction model is represented by P, the segmented image of the real image is represented by G, the volume of the predicted segmentation results is represented by VP and the volume of the segmented real image is represented by V G. Equations (2) and (3) display the expressions for h (P, G) and h (G, P), respectively.
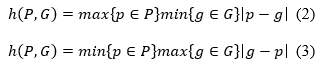
T he accuracy of the segmentation increases with the size of the sorensen dice coefficient. To confirm the efficacy of the suggested modules, this paper runs tests using the BCCS dataset. Table 1 displays the outcomes of the experiment.
| Model | AVD | HD |
| 3D U-Net | 8.65 | 3.24 |
| 6.25 | 3.12 | |
| 3D U-Net +MEM | 5.52 | 2.96 |
| 3D U-Net +MEM+DCRA | 5.51 | 2.52 |
| 3D U-Net +MEM+DCRA+IPD | 4.25 | 1.29 |
Tab. 1. Results of ablation experiments on the brats'20 dataset.
Discussion
Deep learning models are commonly assessed using metrics like Jaccard's Index and the dice coefficient, particularly in the context of semantic segmentation tasks. The dice coefficient evaluates the similarity between the ground truth mask and the predicted output, while Jaccard's Index quantifies the intersection between them. As illustrated in Figure 10, the dice and jaccard coefficients for the individual classes of the proposed model show that the lowest jaccard value was obtained with U-Net, while the proposed model achieved the highest dice score. Similarity coefficients are frequently applied in assessing segmentation algorithms against a ground truth or established reference mask. When comparing two different imaging modalities, the precise extent of the tumor or ground truth is often unknown, necessitating careful interpretation of the similarity coefficient values since they might be deceptive. T his study utilizes a 3D U-Net as the foundational network, without the inclusion of MEM, DCRA or IPD modules. The segmentation performance has shown improvement with the progressive incorporation of MEM, DCRA and IPD modules into 3D U-Net. Except for the AVD indicator, all other evaluation metrics for 3D U-Net have enhanced since the addition of the MEM module; this is evident when the network is defined as 3D U-Net+MEM. Specifically, the dice score improved by 4.89 and 6.13 percentage points, respectively. When the DCRA module, represented by the network version 3D U-Net+MEM+DCRA, was integrated into the 3D U-Net+MEM framework, six evaluation indicators showed improvement compared to the results from 3D U-Net+MEM. Among these improvements, the Dice and Jaccard scores rose to 91.25% and 88.45%, respectively, up from 72.28% and 81.25%, as presented in Figure 10. This indicates that the dual-channel cross reconstruction attention module proposed in this paper can effectively extract features from multiple modalities, thus enhancing the segmentation network's performance.

Fig. 10. Predictions with proposed model on BCCS dataset: From left to right a) Original b) Ground truth c) 3D U-Net+MEM d) MCRIP-UNet.
A fourth set of experiments was carried out using the 3D U-Net+MEM+DCRA+IPD framework to confirm the effectiveness of the IPD module. Table 1 shows that the best segmentation results were obtained by the 3D U-Net+MEM+DCRA+IPD framework; thus, the algorithm proposed in this paper has better performance in feature extraction and segmentation. The proposed segmentation network model has almost twice the number of parameters, but it also has a higher improvement in terms of segmentation accuracy compared to the 3D U-Net. However, its rate of operation is much lower than the 3D U-Net network. Including different modules, the number of parameters needed for the model and each 32 - 32 performance: Table 2 provides the comparison of the runtime of 32 3D images.
| Models | Model Parameter quantity/107 | Running time/ms |
| 3D U-Net | 2.25 | 196 |
| 3D U-Net +MEM | 3.35 | 258 |
| Propose model MCRIP-UNet | 3.58 | 352 |
Tab. 2. Model parameters and runtime.
Table 2 shows that, while MCRIP-UNet has a higher number of parameters and a longer training duration compared to 3D U-Net, it achieves the best segmentation accuracy as indicated by the data. In the registration phase, the network developed in this study was evaluated against resampling [34], ANTs [35], VoxelMorph [36], ViT-V-Net [37] and TransMorph [38] techniques. The network is trained on the preprocessed dataset, which serves as the training set for the model being utilized. A batch size of one is used, the regularization parameter is set to 4.0, the learning rate (lr) is 4e^(-4) and the total number of training sessions is 1500. The ADAM optimizer is employed for optimization. The results for the BCCS dataset are displayed in the first two rows, while those for the LPBA40 dataset are shown in rows three and four. Figure 11 illustrates the distorted image obtained through the registration method used in this study, while the deformed image produced by the VoxelMorph method for registration. The approach outlined in this research achieves a much more precise capture of features; the registration output is more aligned with the fixed image, as seen in the red box in Figure 8 for breast nervous tissue, middle breast tissue and the edges of breast tissue. This paper proposes a registration network capable of registering images with significant 3.35 3.58 196 258 352 internal structural variations. In contrast to the methods discussed in this paper, although alternative methods can also perform spatial deformation on floating images, they occasionally struggle with inadequate local spatial transformation for addressing local deformation issues, which hinders their ability to accurately register and deform floating images according to the physical properties of f ixed images. This indicates the validity of the algorithm proposed in this work. A crucial factor in assessing deep learning and machine learning models is computational time. There exists a direct relationship between time and the size of the image patch; as the patch size increases, the computational time also rises. Smaller patch sizes enhance accurate detection. Our proposed UMPNet architecture was trained on a parallel computing platform for nearly 12 hours, with an average time of 0.52 seconds required for segmenting and classifying cell membranes and nuclei in test data. The training loss (=2.423) and validation loss (=2.612) curves regarding iteration are depicted in Figure 12. A suitable learning rate is essential for effective learning in CNN models. A low learning rate may slow down the learning process, while a high learning rate might prevent the loss value from converging, leading to a failure in the learning process.

Fig. 11. a) Training and validation loss b) Learning rate curve over steps.

Fig. 12. a) ) Training and validation accuracy b) Training and validation mIoU.
It is recommended to implement "learning rate decay" for optimal results, as demonstrated in Figure 13. This involves gradually reducing the learning rate throughout the training process, making the learning rate dependent on the current epoch count. This approach allows for a faster learning algorithm while minimizing the risk of not converging to the lowest loss value. The primary metric used to evaluate accuracy concerning task outputs for all image segmentation is the Mean Intersection over Union, commonly known as mIoU. The model together with relationship regarding the masks as against ground will be assessed. It is seen that, mIoU of the proposed model is drastically increasing with the number epochs. This indicates our proposed model is fit well to our problem of semantic segmentation with the increased epochs.

Fig. 13. a) ) Recall, precision and F1-score of proposed model during training.mIoU.
T he accuracy measures the overall percentage of correct classifications made by the ML model. Precision, in relation to a specific ML model, refers to the quantity of true positive predictions made for the target class. Recall indicates whether an ML model is capable of identifying all instances within the target class. When selecting a suitable metric, it is important to take into account the costs associated with different types of errors as well as the balance between classes. Figure 14 illustrates the recall, precision and F1 score of the proposed model throughout the training process in relation to the number of epochs.

Fig. 14. a) Focal loss variation with respect to a) α and b) γ.
Loss function
Loss functions gauge how much the predictions differ from the actual values. A lower loss value indicates that the model is very accurate, while a higher loss value suggests that the model's predictions are not very correct. It is crucial for a model to strive to minimize a loss function as much as possible, ideally approaching zero. The model uses the loss function to adjust its learnable parameters, such as biases and weights, which are modified in each iteration through the gradient descent method. Cross-entropy is a common loss function used for binary classification, but it can sometimes be inadequate for multi-class classification challenges. It is derived from the mathematical concept of entropy, which is defined as:
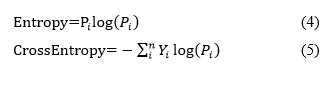
Where Y represents the actual output and P denotes the predicted output from the model. Given that the probabilities range from 0 to 1, taking the logarithm yields negative values; therefore, to ensure the entropy is positive, a negative sign is added in front of the equation. In scenarios with imbalanced classes, the loss function optimized through gradient descent tends to prioritize the majority class, leading to weight updates that enhance the model's accuracy in predicting that class while neglecting the minority classes. A potential solution to this issue is the implementation of focal loss [38].
Focal loss
By concentrating on the instances where the model fails instead of the ones where it can reliably forecast, focal loss makes sure that forecasts on challenging examples get better over time instead of getting too confident with simple ones. This is accomplished by a process termed "down weighting" in focal loss. By lessening the impact of simple instances on the loss function, down weighting emphasizes the importance of difficult examples. By incorporating a modulating factor (µ) "µ=" (1-Pi )^γ³ into the Cross-Entropy loss, this method can be put into practice.
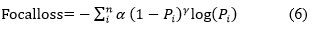
Where the cross validation tunable focusing parameter is called γ (Gamma) and α is weighing factor. The behavior of Focal Loss for various values of γ and α. From figures, the following observations are made:
• Since the pi Is low for the sample that was wrongly classified, the µ is close to or exactly 1 which leads loss function remains unchanged and became a cross-entropy loss.
• As the confidence level of the model increases, that is, as pi equals to 1 µ will tend towards zero. Therefore, the amount of loss that would be made in case of correctly categorized instances will be minimized. In order to reduce the effect of easy instances on the loss function γ re-scale µ so that more easy instances get down-weighted than the hard ones. Focal loss over our dataset gives better performance if γ value equals to 2.
• Focal Loss is similar to cross entropy when the value of γ is 0.
Recall loss
We have employed a new recall-based performance-balanced loss, known as recall loss, to tackle the issue of imbalanced datasets. During the training phase, the model weights are adjusted according to the recall values for each class, guiding them towards minimizing the respective loss function. Unlike the hard example mining approach of focal loss, this method focuses on hard class mining. In comparison to focal loss and other loss functions, recall loss adapts its weights dynamically based on the recall values observed during training for each class. While it improves accuracy, it comes at the expense of the Intersection over union metric, which accounts for false positives in semantic segmentation; our recall loss effectively balances precision and recall for all classes, enhancing accuracy while still achieving competitive IOU scores.
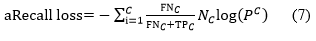
In this context, NC, FNC and TPC represent the number of samples, false positive rate and true positive rate for class C, respectively. The same formula can be applied to other classes if necessary. Recall-loss can be utilized as a standard cross-entropy that is adjusted based on the class-specific FNC. Another key observation is that classes with higher FNC tend to be noisier or more challenging to classify compared to larger classes with lower FNC. As a result, the gradients for the minority classes will receive a boost, while the gradients for the majority classes will be diminished, akin to the inverse frequency loss [39].
Hybrid loss function: In our research, we have incorporated the advantages and disadvantages of the three loss functions mentioned earlier to enhance the learning process and improve the model's performance. The current loss function is a combination of the three previously described loss functions.
Conclusion
Breast cancer ranks among the most common diseases affecting women, which necessitates a more straightforward diagnosis process. The proposed research model aims to implement ultrasound image processing to enhance clinical analysis of breast cancer. This system emulates a classifier model that takes as input the essential features extracted from the layers of the MCRIP-UNet architecture. The introduced algorithm has surpassed traditional diagnostic models through effective feature selection and pre processing. The model’s precision has been thoroughly validated by comparing it with various other models, such as 3D U-Net, 3D U-Net+MEM, 3D U-Net+MEM+DCRA and MCRIP-UNet techniques. The MCRIP-UNet algorithm demonstrates a peak accuracy of 92.33%, exceeding all prior ensemble learning models tailored for breast cancer diagnosis.
References
- Sharmin S, Ahammad T, Talukder MA, Ghose P. A hybrid dependable deep feature extraction and ensemble-based machine learning approach for breast cancer detection. IEEE Access. 2023; 14.
- Fowler EE, Vachon CM, Scott CG, Sellers TA, Heine JJ. Automated percentage of breast density measurements for full-field digital mammography applications. Acad Radiol. 2014; 21:958-970.
[Crossref] [Google Scholar] [PubMed]
- Lin RH, Kujabi BK, Chuang CL, Lin CS, Chiu CJ. Application of deep learning to construct breast cancer diagnosis model. App Sci. 2022; 12:1957.
- Arnout BA. The grief of loss among breast cancer patients during the COVID-19 pandemic: How can palliative care workers help?. Work. 2023; 74:1299-1308.
[Crossref] [Google Scholar] [PubMed]
- Gupta S, Gupta MK. A comparative analysis of deep learning approaches for predicting breast cancer survivability. 2021.
- Dandekar AR, Sharma A, Mishra J. A Deep Learning and Feature Optimization-Based Approach for Early Breast Cancer Detection. In2024 IEEE International Students' Conference on Electrical, Electronics and Computer Science (SCEECS). 2024;24.
- Bouzar-Benlabiod L, Harrar K, Yamoun L, Khodja MY, Akhloufi MA. A novel breast cancer detection architecture based on a CNN-CBR system for mammogram classification. Comput Biol Med. 2023; 163:107133.
[Crossref] [Google Scholar] [PubMed]
- Sengan S, Priya V, Syed Musthafa A, Ravi L, Palani S, et al. A fuzzy based high-resolution multi-view deep CNN for breast cancer diagnosis through SVM classifier on visual analysis. J Intell Fuzzy Syst. 2020; 39:8573-8586.
- Podda AS, Balia R, Barra S, Carta S, Fenu G, et al. Fully-automated deep learning pipeline for segmentation and classification of breast ultrasound images. J Comput Sci. 2022; 63:101816.
- Latha DU, Mahesh TR. Analysis of Deep Learning and Machine Learning Methods for Breast Cancer Detection. In2023 International Conference on Computer Science and Emerging Technologies (CSET) 2023; 10.
- Windarto AP, Wanto A, Solikhun S, Watrianthos R. A Comprehensive Bibliometric Analysis of Deep Learning Techniques for Breast Cancer Segmentation: Trends and Topic Exploration (2019-2023). Sys Eng Infor Technol. 2023; :1155-1164.
- Pour ES, Esmaeili M, Romoozi M. Breast cancer diagnosis: a survey of pre-processing, segmentation, feature extraction and classification. Int J Electr Comput Eng. 2022; 12.
- Aloyayri A, Krzyżak A. Breast cancer classification from histopathological images using transfer learning and deep neural networks. InArtificial Intelligence and Soft Computing: 19th International Conference, ICAISC 2020, Zakopane, Poland, October 12-14, 2020, Proceedings, Part I 19 2020 (491-502). Springer International Publishing.
- Choudhary T, Mishra V, Goswami A, Sarangapani J. A transfer learning with structured filter pruning approach for improved breast cancer classification on point-of-care devices. Comput Biol Med. 2021; 134:104432.
[Crossref] [Google Scholar] [PubMed]
- Mendes J, Domingues J, Aidos H, Garcia N, Matela N. AI in breast cancer imaging: A survey of different applications. J Imaging. 2022; 8:228.
[Crossref] [Google Scholar] [PubMed]
- Shakya A, Singh K, Saxena A. An Adaptive Deep Learning Technique for Breast Cancer Diagnosis Based on Dataset. In2023 3rd International Conference on Technological Advancements in Computational Sciences (ICTACS) 2023; 1.
- Zebari DA, Haron H, Sulaiman DM, Yusoff Y, Othman MN. CNN-based Deep Transfer Learning Approach for Detecting Breast Cancer in Mammogram Images. In2022 IEEE 10th Conference on Systems, Process and Control (ICSPC) 2022; 256-261.
- Poonia A, Sharma VK, Singh HK, Maheshwari S. Breast Cancer Detection: Challenges and Future Research Developments. In2024 International Conference on Integrated Circuits and Communication Systems (ICICACS) 2024; 1-6.
- Vrdoljak J, Kreso A, Kumric M, Martinovic D, Cvitkovic I, et al. The role of AI in breast cancer lymph node classification: A comprehensive review. Cancers. 2023; 15:2400.
[Crossref] [Google Scholar] [PubMed]
- Mendes J, Matela N. Breast cancer risk assessment: A review on mammography-based approaches. J Imaging. 2021; 7:98.
- Choukali MA, Amirani MC, Valizadeh M, Abbasi A, Komeili M. Pseudo-class part prototype networks for interpretable breast cancer classification. Sci Rep. 2024; 14:10341.
[Crossref] [Google Scholar] [PubMed]
- Sacca L, Lobaina D, Burgoa S, Lotharius K, Moothedan E, et al. Promoting artificial intelligence for global breast cancer risk prediction and screening in adult women: A scoping review. J Clin Med. 2024; 13:2525.
[Crossref] [Google Scholar] [PubMed]
- Zheng S, Lin X, Zhang W, He B, Jia S, et al. MDCC-Net: multiscale double-channel convolution U-Net framework for colorectal tumor segmentation. Comput Biol Med. 2021; 130:104183.
[Crossref] [Google Scholar] [PubMed]
- Yin XX, Hadjiloucas S, Zhang Y, Su MY, Miao Y, Abbott D. Pattern identification of biomedical images with time series: Contrasting THz pulse imaging with DCE-MRIs. Artif Intell Med. 2016; 67:1-23.
[Crossref] [Google Scholar] [PubMed]
- He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition 2016; 770-778.
- Ross TY, Dollár GK. Focal loss for dense object detection. Inproceedings of the IEEE conference on computer vision and pattern recognition 2017; 2980-2988.
- Yin XX, Yin L, Hadjiloucas S. Pattern classification approaches for breast cancer identification via MRI: State-of-the-art and vision for the future. Appl Sci. 2020; 10:7201.
- Tawfik N, Elnemr HA, Fakhr M, Dessouky MI, Abd El-Samie FE. Hybrid pixel-feature fusion system for multimodal medical images. J Ambient Intell Humaniz Comput. 2021; 12:6001-6018.
- Li C, Song X, Zhao H, Feng L, Hu T, et al. An 8-layer residual U-Net with deep supervision for segmentation of the left ventricle in cardiac CT angiography. Comput Methods Programs Biomed. 2021; 200:105876.
[Crossref] [Google Scholar] [PubMed]
- Peng T, Wang C, Zhang Y, Wang J. H-SegNet: Hybrid segmentation network for lung segmentation in chest radiographs using mask region-based convolutional neural network and adaptive closed polyline searching method. Phys Med Biol. 2022; 67:075006.
[Crossref] [Google Scholar] [PubMed]
- Isensee F, Jaeger PF, Kohl SA, Petersen J, Maier-Hein KH. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat Met. 2021; 18:203-211.
[Crossref] [Google Scholar] [PubMed]
- Liu X, Song L, Liu S, Zhang Y. A review of deep-learning-based medical image segmentation methods. Sustainability. 2021; 13:1224.
- Amgad M, Elfandy H, Hussein H, Atteya LA, Elsebaie MA, et al. Structured crowdsourcing enables convolutional segmentation of histology images. Bioinformatics. 2019; 35:3461-3467.
[Crossref] [Google Scholar] [PubMed]
- Xu Zhicheng, He Lianghua. A Medical Image Segmentation Model Integrating Multiscale Features. Comp Knowled Technol, 2023; 19:35-37.
- Ma Y, Hao H, Xie J, Fu H, Zhang J, et al. ROSE: A retinal OCT-angiography vessel segmentation dataset and new model. IEEE Trans Med Imaging. 2020; 40:928-939.
[Crossref] [Google Scholar] [PubMed]
- Fu L, Zhang Q, Lin L, Reyes R. A 3D medical image segmentation method based on MCRAIP-Net. IEEE Access. 2024; 26.
- Li Wei, Wu Cong. Medical image segmentation network based on multi-level residuals and multi-scale. J Hubei University Technol, 2023; 38:38-42.
- Yang Z, Xu P, Yang Y, Bao BK. A densely connected network based on U-Net for medical image segmentation. ACM Transactions on Multimedia Computing, Communications and Applications (TOMM). 2021; 17:1-4.
- Patel Y, Tolias G, Matas J. Recall@ k Surrogate Loss with Large Batches and Similarity Mixup. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022; 7492-7501. IEEE Computer Society.